AMSA
Activity 4: Docker & AWS
THIS ASSIGNMENT IS “DIFFICULT”!
Not because the tasks themselves are hard, but because understanding what the problem is asking can be tricky. You’ll need to be familiar with certain networking concepts before you begin. We’ve linked the relevant resources below. If you feel lost at any point, please email us or stop by our office, we’re here to help.
SO PLEASE MAKE SURE TO READ THE ENTIRE DOCUMENT CAREFULLY AND UNDERSTAND WHAT WE’RE ASKING YOU TO DO
1. Introduction
The objective for this assignment is to dockerize and orchestrate a provided API.
We’ve created an HTTP Server API, a program that communicate between different applications by defining clear rules for how data is requested, sent, and received.
There are lots of different behaviours for APIs (and we’ll explain how ours works in the sections bellow), but they will typically have:
- Endpoints: An API endpoint is a dedicated URL that provides access to a specific resource. For instance, the /articles endpoint in a blogging app would return all the articles of the server.
- Method: The request’s method indicates the type of operation the client would like to perform on a given resource. REST APIs are accessible through standard HTTP methods, which perform common actions like retrieving, creating, updating, and deleting data.
- Parameters: Parameters are the variables that are passed to an API endpoint to provide specific instructions for the API to process. These parameters can be included in the API request as part of the URL, in the query string, or in the request body. For example, the /articles endpoint of a blogging API might accept a “topic” parameter, which it would use to access and return articles on a specific topic.
- Request body: The body is the main part of the request, and it includes the actual data that is required to create, update, or delete a resource. For instance, if you were creating a new article in a blogging app, the request body would likely include the article’s content, title, and author.
The objective of this activity is to dockerize and deploy to AWS our API, while also learning about databases in the way.
2. Delivery
Accept the assignment in Github Classroom, following the link
To complete this activity, you must do the following for each sub-delivery (PRAC-4.1, PRAC-4.2, PRAC-4.3 and PRAC-4.4):
Deliver a link to your Github repository on the virtual campus activity.
Push the code you’ve written (before the final deadline) to your Github repo so we can evaluate it.
Remember that we’re only going to evaluate your assignment after the final deadline, but following the recommended tempos and pushing each part of the activity accordingly can grant you extra points.
3. Outline
This activity is split onto 4 incremental parts, which are going to be related to the contents explained during the different classes.
- On the first week, your job will be to “dockerize” the API.
- On the second week, your job will be to communicate the API with a postgresql database using docker-compose on your local PC.
- Then, we’ll want you to deploy the API to AWS.
- Finally, after having explained the AWS Relational Database Service (RDS), you’ll connect the ECS service to your newly created RDS database.
4. Resources
Since building the users API yourself is outside the scope of this subject, the teachers have prepared some helpful resources to make the activity quicker and more enjoyable. This way, you can focus on the fun parts: containers and AWS services!
Repository template
When you join the Github Classroom activity with the link provided on Step 2, a remote repository is automatically created for you to work on this assignment. This repository will already contain all the python code of the API, below are the details of what comes with the repo:
It has everything needed to serve the API.
A
README.mdfile where you’ll have instructions on how to set up the python environment.
Understanding the API
How does our API work? First, you have to setup your environment and start the server, see section 6.
By default, the server listens for HTTP connections on port 8000. Be aware that, this means that if you’re running it on your pc (without any container), you can access it via http://localhost:8000 on your browser. If you’re running it on a conainer, you’ll need to map the port of the container to your host so you can access it on your browser (see how to map it on our reference cheatsheet).
The API, exposes three “endpoints”, let’s see them:
(
GET /docs) Documentation: Returns an html file (the type of files that your browser knows how to show/paint on the screen), that allows us to easily call the other two endpoints of the API. 1(
POST /users) Create a user given:- A username
- A name
- A role (“user” or “admin”)
- A password
(
GET /users) List all existing users
If you want to see the documentation and “play” with the /users endpoints, you can access http://localhost:8000/docs 2 This will allow you to create users with POST http://localhost:8000/users, and then retrieve the information with GET http://localhost:8000/users, nice!
If it still didn’t make clear what an API really is watch the hardvard cs50 http class, and then think that:
- The
/docsendpoint is just the same as the “facebook” example they show, it returns text inhtmlformat. - The other two endpoints, (
POST usersandGET users) receive and return text in the json format, nothtml.
The database
You’ll switch and explore the databases on PRAC-4.2! Although it is recommended that you try to understand them now, so you can “more or less” see, how our service works!
Our app needs a way to save the users information! We save it on a database, and we want to choose between different databases 3 :
By default, it uses an internal sqlite, which just uses a “raw” file as the database. This means that it doesn’t connect to anything, it just saves the information to an “optimized” file, and that’s really it.
If the
PRODenvironment variable is set 4 , then it will attempt to connect to a postgresql database. This database is another “service” on his own, that exposes a port (by default 5432), where you can connect and send values to be saved. Of course, not everyone should connect to this database, only the people with a valid username and password, that’s the reason behind that, when you create a postgresql database, you need to tell it the user and password that you want!
Once we have an instance of postgresql running, we can tell the users api to use this instance instead of the sqlite one (This will be a requirement on Prac-4.2!). So, we’ll have to tell him the following information via environment variables:
PROD: Set it to true if you want to use a postgresql instance.DB_USER: The user who will connect to the databaseDB_PASSWORD: The password to connect to the databaseDB_HOST: The IP address of the host of the databaseDB_PORT: The port of the host of the databaseDB_NAME: The name of the database inside postgresql
Brief summary
A brief summary of how the app works is shown below (using user creation (POST /users) as an example): 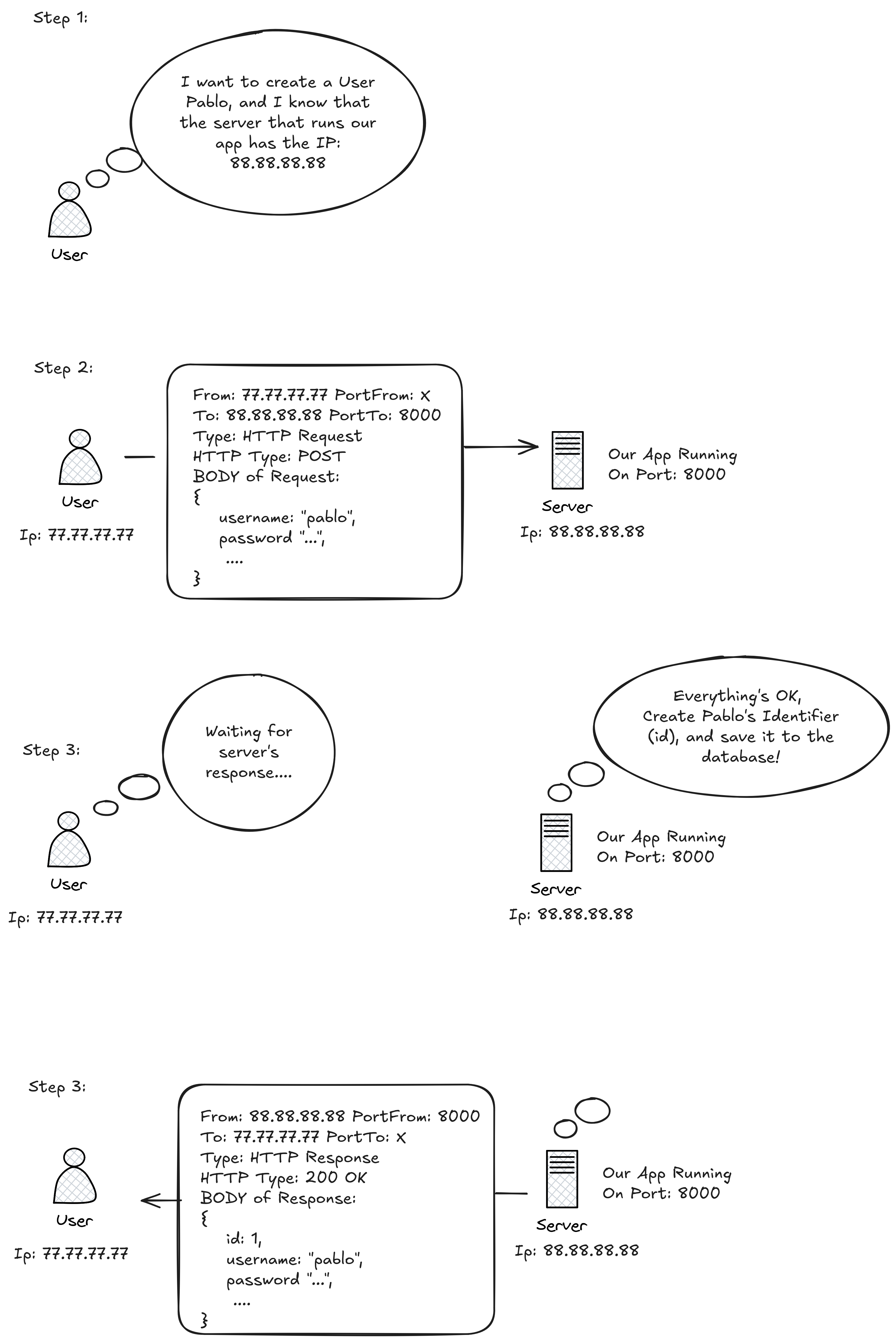
Keep in mind that if you’re running everything on localhost (which is likely the case for PRAC-4.1 and PRAC-4.2) the IP address used in the example figure will be 127.0.0.1, or simply the domain name localhost. In this setup (PRAC-4.1 and PRAC-4.2), your machine acts as both the server and the client.
5. Tasks
Prac-4.1: “Dockerizing” the API
Your main objective is to “dockerize” the API. That’s it, we keep it simple this week. So you should write a Dockerfile to run the users API http server inside a container. The rules are the following:
- Keep in mind that the command you must run inside the Docker container is uv run fastapi run, and that dependencies must be synced before (this means the virtual environment should be created before doing the
uv run). - You must only use the sqlitedb database! This means that, in prac-4.1, you don’t have to
docker runwith custom env variables, just the default ones!. - Remember to map the container’s port to a port on your host machine, otherwise, the server will remain isolated inside the container and you won’t be able to access it from your host.
- If you have any questions about what you’re allowed to do in the Dockerfile, please ask the teachers.
Your goal should be to make the resulting image as small as possible, as that’s what good developers should do!
Prac-4.2: Moving to Docker Compose
Your objective is to switch the API’s db to a postgresql, and communicate it through Docker compose
- Move the dockerized image onto a compose service. This should be a straight-forward step.
- Deploy a postgresql database on the compose. Don’t stress on joining them yet!
- Now it’s time to communicate them.
- Lastly, make sure that the database persists the information even if the container is removed.
The resulting file should be a docker-compose.yml with both services and their respective configuration.
The topology should be something like this: 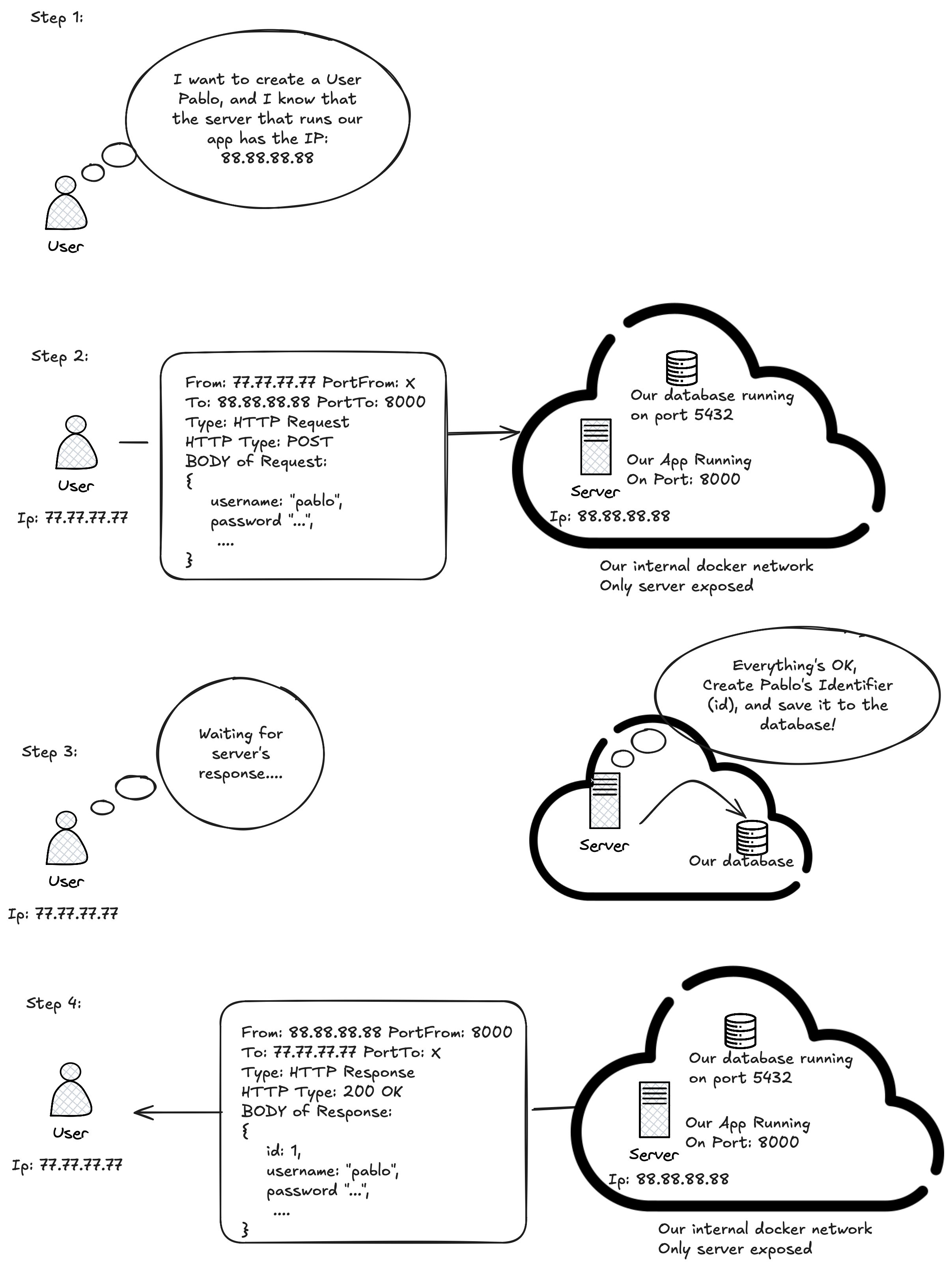
You can see the logs of the container for asserting that it is using the PostgreSQL database (you can see the code that does this here ).
Also, you can connect to the database and query the tables! See this cheatsheet for connecting and querying postgresql
Feel free to use PostgreSQL 18 or 18.1 (there’s no meaningful difference for our use case).
Prac-4.3: Using AWS ECR and ECS
Deliverable
For the deliverable, you have to create a /documentation/prac_4_3 folder on your github project 5.
This folder, will contain:
- the screenshots of the steps you’re doing to create the aws services (no need to make screenshots about login to aws, etc, etc), just the ones that shows how you’re creating the services and one that asserts that your service is running (an http request and response to the public api…)
- A markdown file named
README.mdthat explains in less than one paragraph each step, referencing the screenshoot you’re talking about.
An example of the file would be:
# Deploying the ECS service
## Step 1: One step
Explain something here, we reference it on the following image:

## Step 2: Two step
We do X because Y, the following image shows how to configure it:
Description
Understand what you’re doing. Not just what you’re clicking
The PRAC-4.3 and PRAC-4.4 assignments may look like simple “click-through” tasks on the AWS console. In fact, even our grandma with zero cloud/virtualization/containers could do it with time and effort.
But that’s not the goal.
You need to understand why you’re clicking those buttons, what each service actually does, and how it works under the hood. The value isn’t in completing the steps, it’s in learning the concepts and the architecture behind them.
Your objective is to deploy the API to the aws cloud. We’ll deploy them in her basic way, with sqlite as the database backend, so no need to deploy a postgresql for now 6.
For this deployment, we’ll use the Elastic Container Registry (ECR) and Elastic Container Service (ECS) services. We will not deploy using a raw EC2 instance with Docker, you should understand why (see the Week-12 slides for a refresher).
In the end, we’ll arrive at a setup similar to the following schema. It’s not very different from PRAC-4.1, but this time we treat the API as a “black box” that we’ll configure later through the AWS UI:

In AWS, this “black box” maps to an architecture with the services shown in the figure below. Keep the following in mind:
Blue components represent the services you MUST create for this assignment.
Red components are NOT relevant right now. they will be used later in PRAC-4.4.
You DO NOT NEED to create any services that are not highlighted in blue. However, you NEED TO CONFIGURE THE BLUE SERVICES SO THAT THEY CORRECTLY REFERENCE AND USE THE RESOURCES they’re connected to in the diagram.
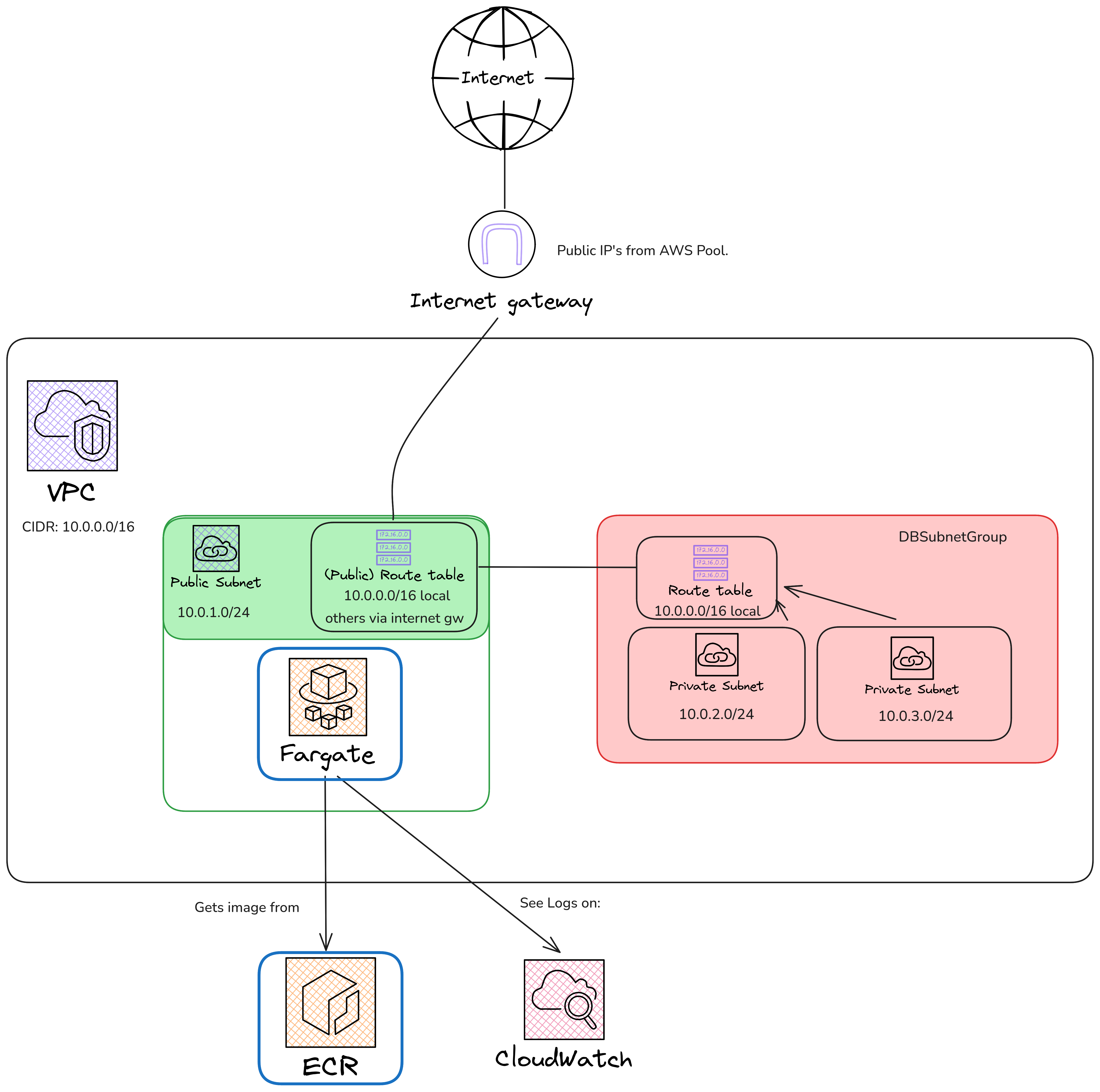
Steps
Okay, now that we understand the architecture we’ll be building, the next steps are as follows:
- Login to AWS academy and start the lab
- Create a registry and upload the image to it:
- Create an ECR Registry
- Upload your container image to the ECR Registry.
- Create the ECS in fargate mode:
- Create a Task Definition for our ECS.
- Create a Task with the definition we configured on the previous step.
Let’s se them step by step.
1) Login to AWS academy and start the lab
The first step is to open the AWS Academy webpage and start the lab. Since you’ll be doing this frequently, it’s also listed on the resources page, you can find it here
2) Create an ECR Registry
This step is straightforward: simply create a registry using the namespace and repo-name you prefer.
For Image tag mutability, choose the option that fits your workflow. Keep in mind:
- Mutable tags allow you to overwrite existing tags. This means you can push multiple images with the same tag. The most recently uploaded image will take over that tag.
- Immutable tags prevent overwriting. If an image is already tagged with a name, you won’t be able to push another image with the same tag name.
For encryption settings, you can leave the default configuration, we don’t need to adjust anything there
3) Upload your container image to the ECR
To upload the image, the AWS ECR page includes a very useful View push commands button that walks you through the exact steps needed to push an image to your registry. The aws guide assumes that you’ve already installed and configured the AWS CLI with your credentials.
If you haven’t done that yet (and you probably haven’t), start by following our guide on installing and configuring the AWS CLI. You can find it here
Once you’ve configured the AWS CLI, the steps that the aws guide shows you are straightforward:
Log in to AWS using your CLI credentials.
Configure Docker so it recognizes your registry and uses your AWS CLI credentials.
Build your Docker image.
Push the image to your ECR registry.
4) Create a Task Definition for our ECS.
- The launch type should be
fargate - The architecture should be
Linux/X86_64if you builded the image with anx86_64computer, orLinux/ARM64otherwise (Mac M1, M2, M3, M4 users, and MicroChof Windows Snapdragon users) - For the
loggingvalues, left the default ones.
Please, be aware to create the task definition with the less usage of resources possible!
5) Create a Task from our definition
- You should create the task on the
amsa2526-ECSCluster. - On Networking, use our VPC
amsa2526-vpcand our public subnet… - Use our already existing SecurityGroup:
amsa2526-svc-sg - Enable auto-scaling to allow more resource usage during high demand, allow scaling up to a maximum of five instances when needed.
- Turn the public IP on.
Please, be aware to create the task with the less usage of resources possible!
6) Test the Service!
You should be able to access the public IP that Amazon assigned to your task on port 8000 and view the /docs page.
Prac-4.4: Merging it with AWS RDS!
Deliverable
For the deliverable, you have to create a /documentation/prac_4_4 folder on your github project
This folder, will contain:
- the screenshots of the steps you’re doing to create the aws services (no need to make screenshots about login to aws, etc, etc), just the ones that shows how you’re creating the services and one that asserts that your service is running (an http request and response to the public api…)
- A markdown file named
README.mdthat explains in less than one paragraph each step, referencing the screenshoot you’re talking about.
Description and steps
Now we’ll connect our ECS created on PRAC-4.3, with an RDS instance. The steps will be as follows:
- Login to AWS academy and start the lab
- Create an RDS instance, with our own user and password.
- Edit the ECS configuration so has the needed environment variables for connecting to the RDS.
And the resulting architecture diagram should be the following one:
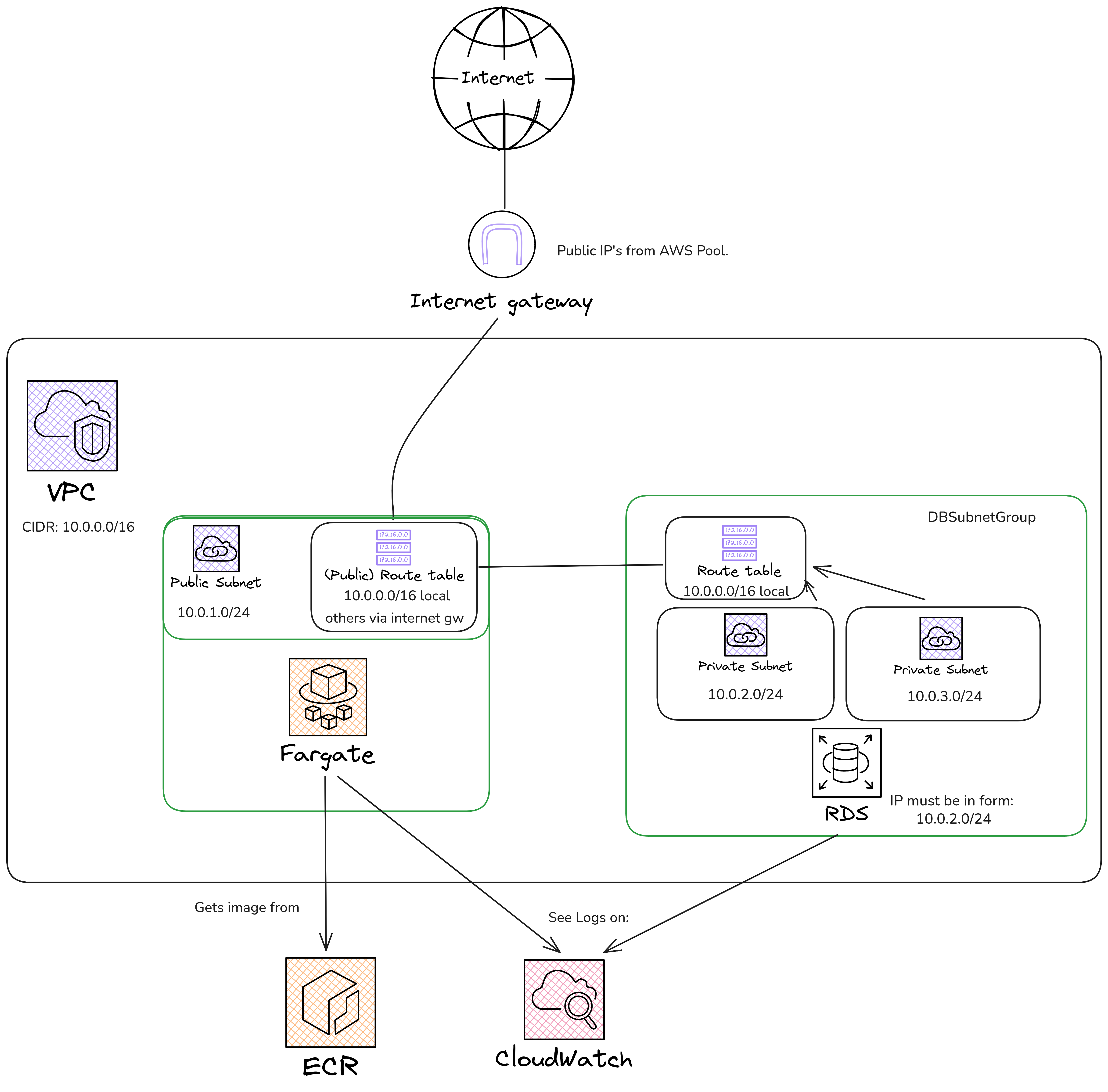
2) Create an RDS instance.
Create an RDS instance with the following specifications:
- Choose PostgreSQL as the engine, with version 18.1-R1.
- You’ve to use a single AZ (Availability Zone).
- You’ll probably want it
Self-Managedfor configuring your own password… (for the env variables) - The instance configuration MUST be
db.t3.micro(is the only one allowed for our AWS LabRole..) - Connect to our VPC (
amsa2526-vpc). - Use the db subnet group (
amsa2526-dbsubnetgroup). - Security group should be the
amsa2526-DBSecurityGroup. - For the Availability Zone by default, see the architecture diagram, which one we’re using….
- For all other options, choose wisely and explain your choice in the document
3) Edit the ECS configuration
At the moment, the API running on ECS is creating an SQLite file and using it as the database. You should be aware of this, as you already fixed the same issue locally in PRAC-4.2.
You’ll need to:
- Edit the task definition from
PRAC-4.3 - Add the needed environment variables to the task defintion
- Re-deploy the ECS task!
⚠️ Warning: Attempting this in a real production environment may cause serious issues.
Please note that this is a “playground” lab. In a real production environment, you would likely need to take the following points into account:
Hardcoding the password and potentially sensitive env variables on the ECS specification isn’t the best security practice. You’ll probably want to use the AWS Secrets Manager or the AWS Systems Manager Parameter Store for storing secret materials.
RDS it’s not a cheap service! In fact, you can have fun calculating the price here 7. Probably if you are using this on production you’ll have to optimize your SQL-Queries (this means, don’t use an ORM, like for example: SQLAlchemy for python, prisma for next-js, etc.). You can also use other “cheaper” services like for example Aurora Serverless V2
6. Setting up the server!
Cloning the repository and set it up:
Remember that, once you entered the Github Classroom on section 2, you will have to clone your repository with:
git clone <ssh_address_of_your_git_repository>Then, setup a virtual environment for the python project, which can be done with:
uv syncNow, you’re ready to run the users api server, do it with:
uv run fastapi run7. Evaluation
Your final score will come from various parts:
- 4.1: Docker → 15%.
- 4.2: Docker-Compose → 15%.
- 4.3: ECR & ECS → 15%.
- 4.4: RDS → 15%.
- Best practices are used → 40%.
- How small is your Docker image?
- Is your compose deterministic?
- Does your compose expose more than needed?
- …
8. Rules
- It is forbidden to modify our python code (the given API). It has everything you need and there’s no need to modify it. If you feel like modifying the code would make something better, contact the teachers before doing so.
- In the
Dockerfilefor the user API, the dependencies must be installed in the Docker, not in runtime - If you are a group of 2, both of you must contribute to the repository with at least 1 commit.
9. Resources
10. Doubts
Please don’t hesitate to ask the teachers any doubts, there are no dumb questions, we’re here to help.
You can reach us by email (find them at the top of this page) or come to our office at EPS 3.07 (we’re here mostly during mornings).
Footnotes
The
http://localhost:8000/docswebpage, isn’t the only way to “test” the endpoints of the API. Our server exposes a connection http on the port8000, so any clients that support thehttpprotocol could be used instead. If you’re curious, you can use another client like for example postman (see video here) or if you want a cli tool that is installed on every linux distro, just use curl↩︎In reality, you could also access http://localhost:8000 instead of http://localhost:8000/docs, since it will automatically redirect you to
/docs, you can see the code of the server that does this↩︎A database is just a program that makes saving and retrieving data easy and fast. We could save our users inside a file named “users.txt”, ex:
1,pabloteach,Pablo Fraile,admin,4346%3450834 2,ori,Oriol Agost,admin,435-08345237 ...But, of course, this would be slow as f**k, that’s why we use databases.↩︎
If you don’t know what environment variables are (you should know it from the Operating Systems course), you can have a great explanation on the hpc-wiki↩︎
This means that you’ll probably want to add this folder to the .dockerignore….↩︎
In fact, we’ll do this on PRAC-4.4!↩︎
Our current configuration, which has sh*t specifications, costs us 183.60 USD per year, which are 15.3 USD per month! 💀↩︎